

 A culture killer is what ruins workplace culture in spite of your every effort. When we were researching our new book,
A culture killer is what ruins workplace culture in spite of your every effort. When we were researching our new book, Is it a sign of weakness in your organization to say “I don’t know?” Is it a requirement that you be certain all the time?. There is a name for an annoying adult who hogs the conversation with dubious facts and stalwart opinions, often wrong, but never in doubt. Such a person is called a “know-it-all.”
There are some organizations that appear to be entirely populated with know-it-alls. Listen in on meetings, on groups trying to make a decision. How did the organization hire 100% know-it-alls?
It didn’t. It created them by establishing the perverse rule that admitting you don’t know something is admitting weakness. You betray weakness by admitting you are not on top of it, no matter what it is. The unspoken rule is:

Never say I don’t know, even if it’s true.
If you feel that you lose status by saying “I don’t know” recognize that you are living a fraud. Healthy organizations are full of I-don’t-know-admitters. Telling the truth is okay, really
 Tom DeMarco’s speculative novel,
Tom DeMarco’s speculative novel, 
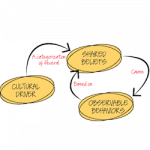 How workplace culture affects workplace performance: We know they’re linked, but now we know a bit more about how and why:
How workplace culture affects workplace performance: We know they’re linked, but now we know a bit more about how and why: 







